本文共 952 字,大约阅读时间需要 3 分钟。
问题的核心点在于多线程进行扩容的时候每个线程会生成一个新的hashtab对象,线程A生成新的hashtab以后,线程B在线程A新生成的hastab上进行操作会造成死循环。
可以参考jdk1.7的hashmap扩容问题的文章。
核心摘录
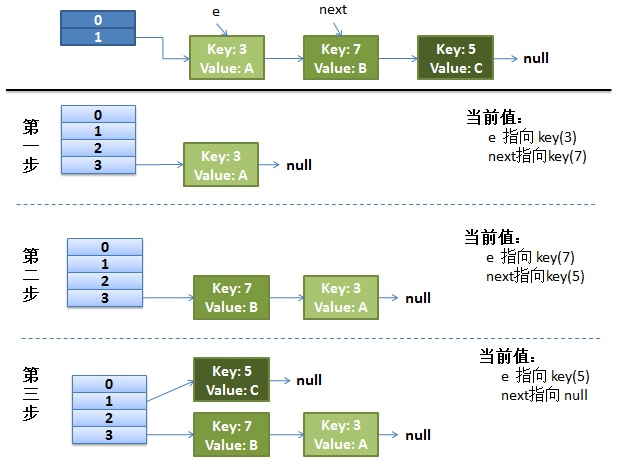
正常的ReHash的过程
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
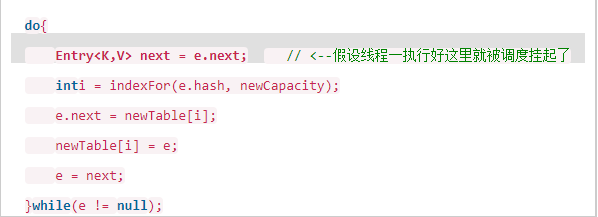
我们再回头看一下我们的 transfer代码中的这个细节:
而我们的线程二执行完成了。于是我们有下面的这个样子。
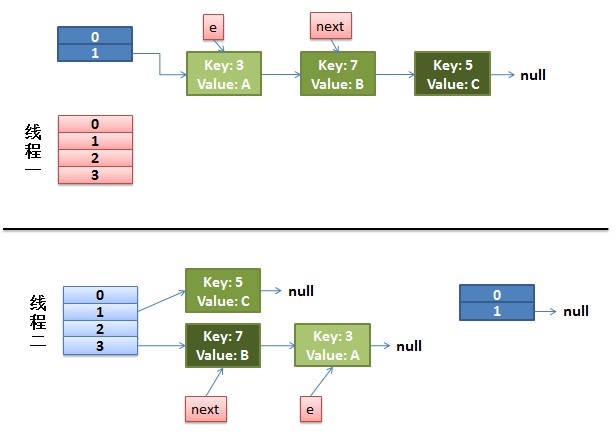
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
先是执行 newTalbe[i] = e;
然后是e = next,导致了e指向了key(7),
而下一次循环的next = e.next导致了next指向了key(3)
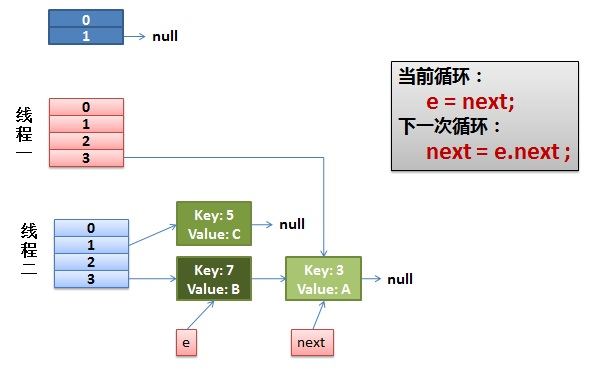
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
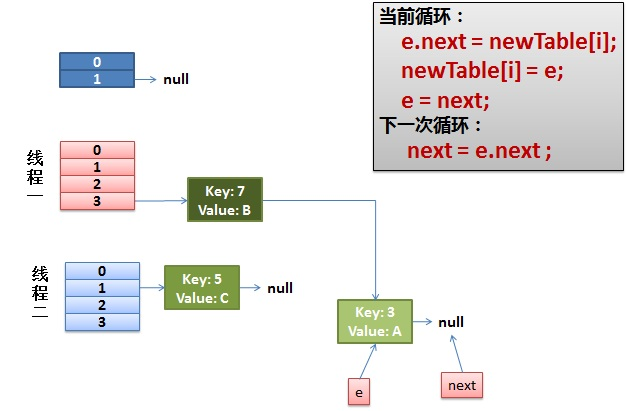
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
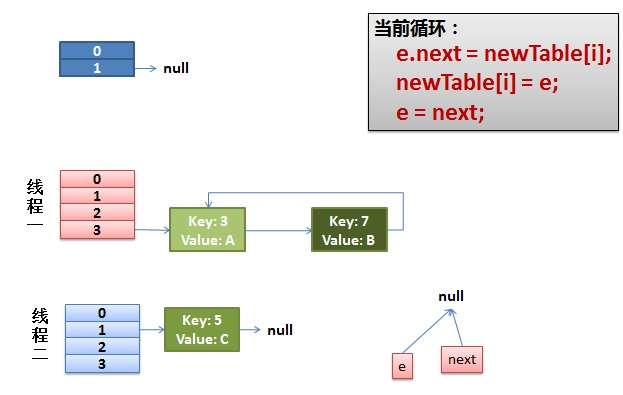
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
此时两个线程put完毕,线程二先完成rehash,之后再线程一rehash,线程一最终put的链形成了闭环,但是这两个线程没有死循环,只是后来get的线程如果进入这个闭环链,就死循环了,并且进入的线程越多,CPU消耗的越大,最终到达100%
参考文章
jdk1.7:
jdk1.8:
转载地址:http://rtkfm.baihongyu.com/